Making Django Deployments Less Disruptive
Disruptive Deployments
One backend application I used to work on was written using the Django framework, and production web servers were powered by Gunicorn: whenever we performed deployments, the gunicorn workers were restarted (to be more accurate, they were stopped and started again).
However, restarting the production Gunicorn workers was usually followed by a period of increased latency on the user side for a few minutes:

After a brief initial investigation, we were able to make some guesses about the factors contributing to this issue:
- Gunicorn starts accepting connections too early, before the application source code has been loaded.
- The application source code is only being loaded once the first request is being received, not before.
- Each Gunicorn worker is loading the application code separately for itself. For example, if you are running Gunicorn with 16 workers (with
gunicorn —-workers=16 —-bind=0.0.0.0:3000 wsgi), the application source code will be loaded 16 times, effectively affecting at least 16 different requests. - Loading the Django code is a slow operation, causing the first request to hang until the code is loaded. Additionally, other requests will be received by Gunicorn in the meantime and will be queued until the Gunicorn worker is available, exacerbating the issue by further increasing the server load and leading to a larger number of requests affected by higher latency.
Later on, we did a more thorough investigation and were able to confirm these assumptions. This article will present the simple solution, before diving into more details through an overview of Gunicorn and Django initialization flow to better understand why the solution is efficient.
A simple fix
As often with challenging issues, the investigation can be a tumultuous journey ending with a fairly simple solution. For this particular problem, the resulting fix was as simple as:
- Starting our Gunicorn workers with the
--preloadargument. - Adding 3 lines in our
wsgi.py. These are the last 3 lines in the code snippet presented below:
These two simple changes enabled us to perform more transparent deployments for our users by avoiding latency spikes after restarting the Gunicorn workers.
The rest of this article will explain why this fix works by giving more details about the Gunicorn and Django initialization process.
Gunicorn Preloading
A brief reminder of Gunicorn design
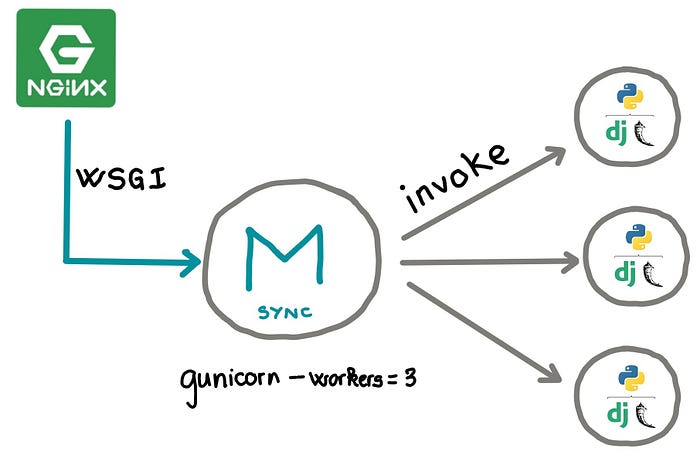
First of all, it's important to remember the high-level architecture of Gunicorn. Gunicorn is composed of two main entities: a master process and multiple worker processes.
- Master Process
This is the main process that is created when you start gunicorn.
It acts as a coordinator: it binds the server socket, receives and accepts incoming connections, and dispatches requests to the worker processes. - Worker Processes
These are the actual processes that will handle the HTTP requests and execute the Django application code.
These processes are created and managed by the master process: for example, if one of these processes crashes, the master process will detect it and automatically spawn a new worker to replace it.
There are different types of worker processes, such as Sync Workers that can only process one request at a time, or multi-threaded Async Workers.
The Gunicorn documentation gives more details about this design and gives a good overall summary:
Gunicorn is based on the pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.
This other Medium article is also a solid resource to learn more about the different concurrency models supported by Gunicorn.
Gunicorn Initialization Flow
By default, Gunicorn does not preload the application code. Instead, it does the following operations:
- Create the Master Process.
- The Master Process binds the webserver socket and starts accepting connections.
- Spawn the Worker Processes.
- Each Worker Process loads the application code separately when receiving their first request.
Fortunately, Gunicorn exposes the --preload option to tune this initialization process. When using the --preload, the initialization flow becomes:
- Create the Master Process.
- The Master Process loads the application code
- Spawn the Worker Processes. Recall that Worker Processes are created by forking the Master Processes, meaning that the workers are spawned with the preloaded code.
- The Master Process binds the webserver socket and starts accepting connections.
The documentation does not give many details about --preload, but states the following:
Command line: --preload
Default: False
Load application code before the worker processes are forked.
By preloading an application you can save some RAM resources as well as speed up server boot times. Although, if you defer application loading to each worker process, you can reload your application code easily by restarting workers.
Unfortunately, preloading the application code by using Gunicorn's --preloadis not enough. As we will see in the next section, Django performs a lot of lazy-loading, preventing most of the application code to be preloaded, and effectively limiting the usefulness of --preload.
Django Initialization
This section only considers WSGI initialization, which is used for Gunicorn. The Django shell or runserver may have a different initialization flow, though it is likely to be similar.
In wsgi.py, the Django application is loaded by calling:
We can check further what this function does by checking the Django source code. I annotated the source code with some comments to summarize the logic:
Thus, as you can see, preloading Django source code using Gunicorn’s --preload is quite limited. In the initialization process, Django only performs the following:
- configure the loggers
- prepare the Django apps configuration
- preload the models
- preload the middlewares
- prepare the middlewares chain
Only a tiny part of our source code is being preloaded at that point. Even our urls.py files are not loaded at that stage. Everything else, including these urls.py files, will be loaded later on once receiving the first request.
This first request will be processed by WSGIHandler.__call__, which basically goes through the middlewares call-chain prepared previously.
From there, it is easy to find what causes the requests to hang after a fresh Gunicorn restart. At some point, Django needs to dispatch the request to the appropriate function and needs to access the urls.py configuration. It is only at that point that our urls.py will be loaded, which in turn will import the rest of our source code.
By studying the Django initialization code, there does not appear to be any configuration option to force this preload. The only way to preload is to call the urls.py loading logic in our wsgi.py, such that it can be part of the Gunicorn preloading flow.
It can be interesting to better understand what this code does to see why it would effectively preload our application source code.
From there, you can see that just calling get_resolver(ROOT_URLCONF) does not do much per se. It will initialize a RegexResolver object, but this RegexResolver does not do much in its __init__ function. However, get_resolver(ROOT_URLCONF) will cache this RegexResolver using @lru_cache, meaning that anything that we load using the returned RegexResolver will be saved for any future logic calling get_resolver (which is what the WSGIHandler.__call__ does).
This is where calling RegexResolver.url_patterns (i.e.: get_resolver(ROOT_URLCONF).url_patterns) is useful as it will preload all our urls.py, which in turn will preload all our application code (the urls.py import our views, which in turn import the rest of our application code).
To better understand how the urls.py are preloaded by RegexResolver.url_patterns, you will need to read the source code of django.conf.urls.url and django.conf.urls.include. It's out of the scope of this explanation, but you can roughly picture these as initializing many other RegexResolver instances.
Conclusion
Django is a popular web framework, and you can quickly build large applications with it. For the most part, these applications can run with great reliability!
That being said, from my experience, there are a few small things causing Django to fall short when operating it in a production environment. For the most part, these are a lack of proper documentation on relevant production-related behaviors and internals deep dive, or inappropriate and unexpected default behaviors, like the one presented in this article. Other popular python tools actually suffer the same issue (for example celery and its -Ofair).
Additionally, I have seen too many other engineers working on very complex solutions just because they just shy away from digging into the code base of open source projects that their entire service is built upon when the documentation is falling short.
Thus, this kind of challenge is a good reminder that a quick dive into the source code of the tools you are using can be extremely valuable: not only it helps you to better understand these tools, but mostly it can help you to find easy, unexpected and powerful solutions to some of your problems.
